The Process: How I Talked My Way Into Building a Watch Research Platform
A companion post to “Time is Money” — the story behind the story.
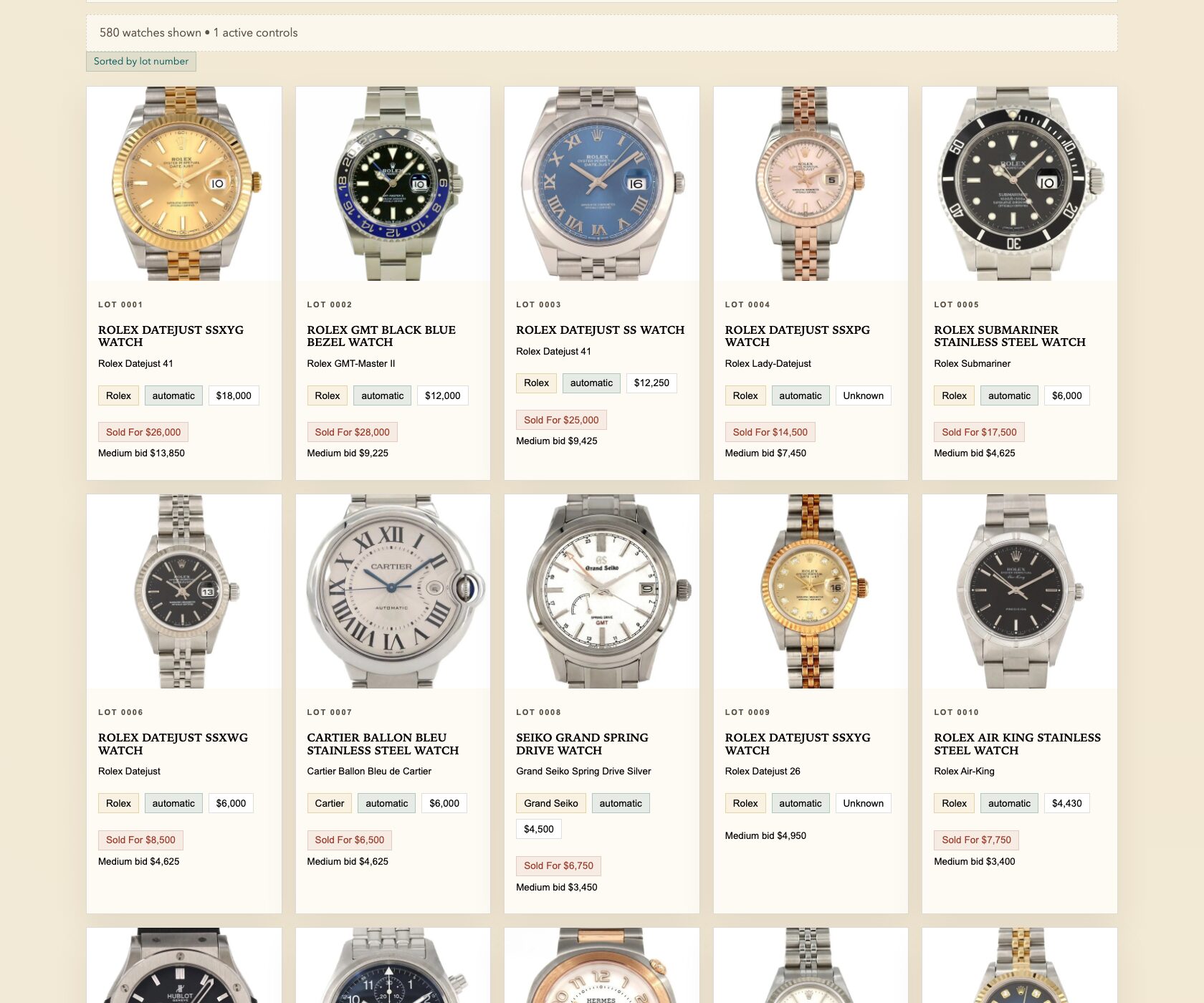
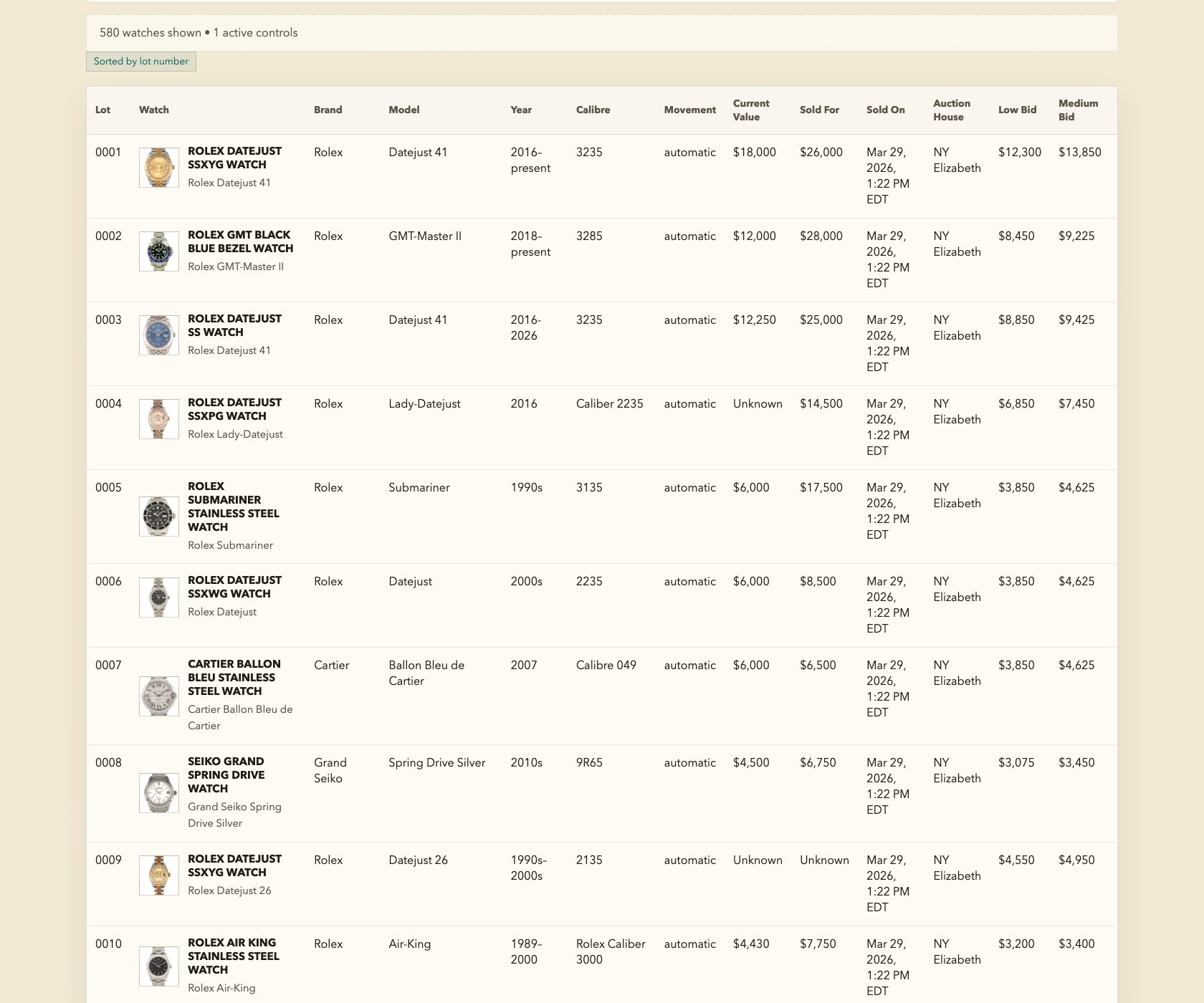
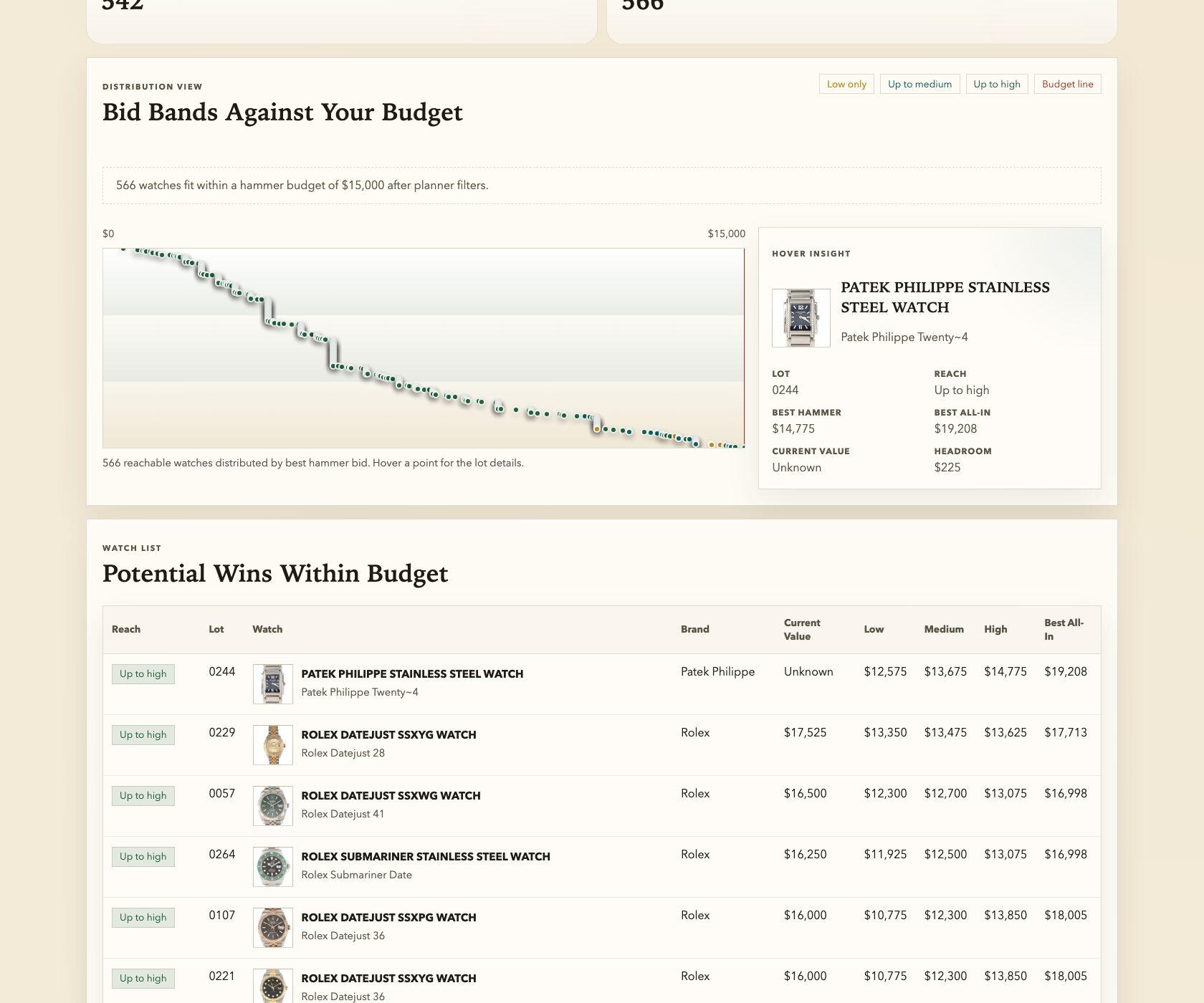
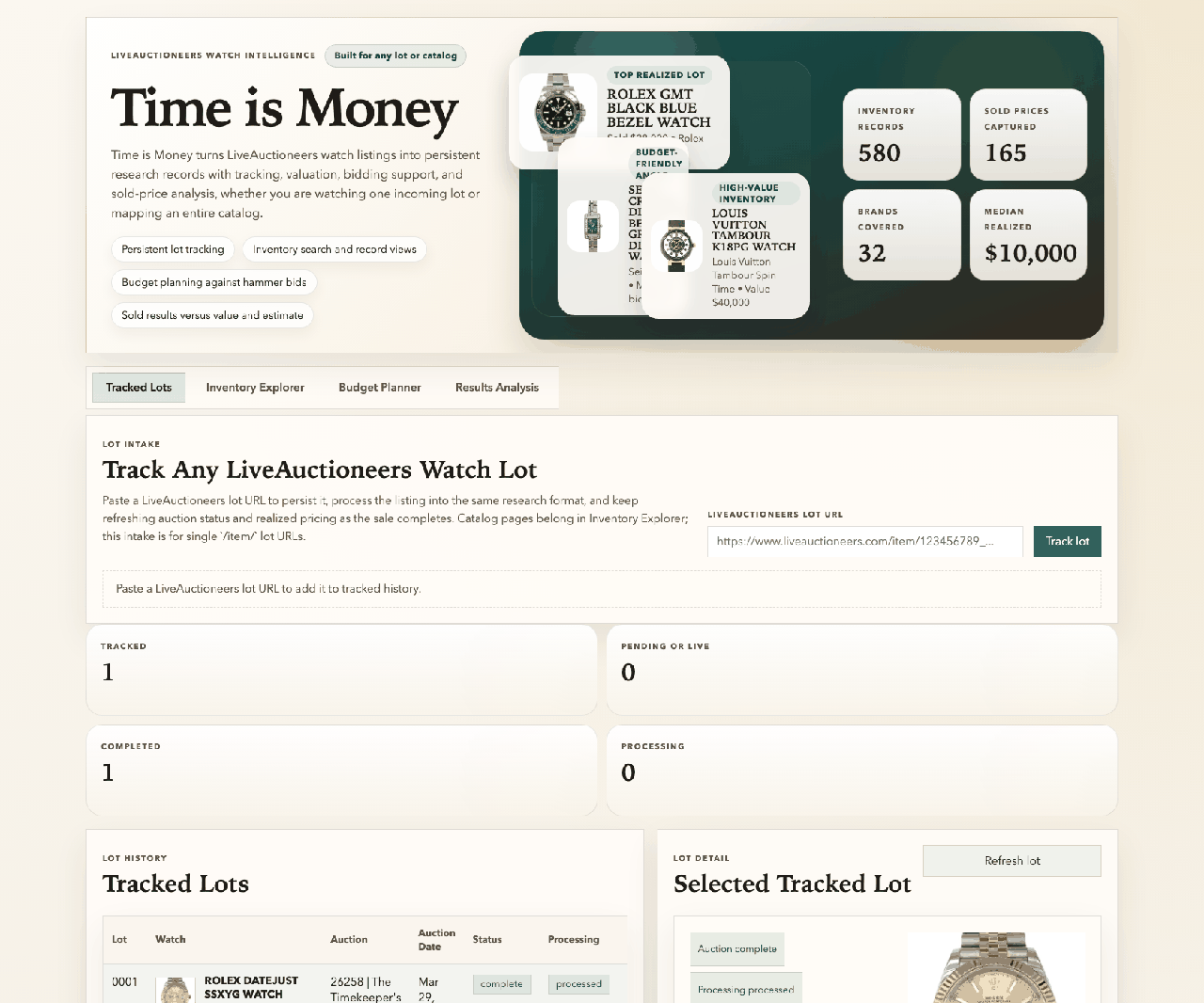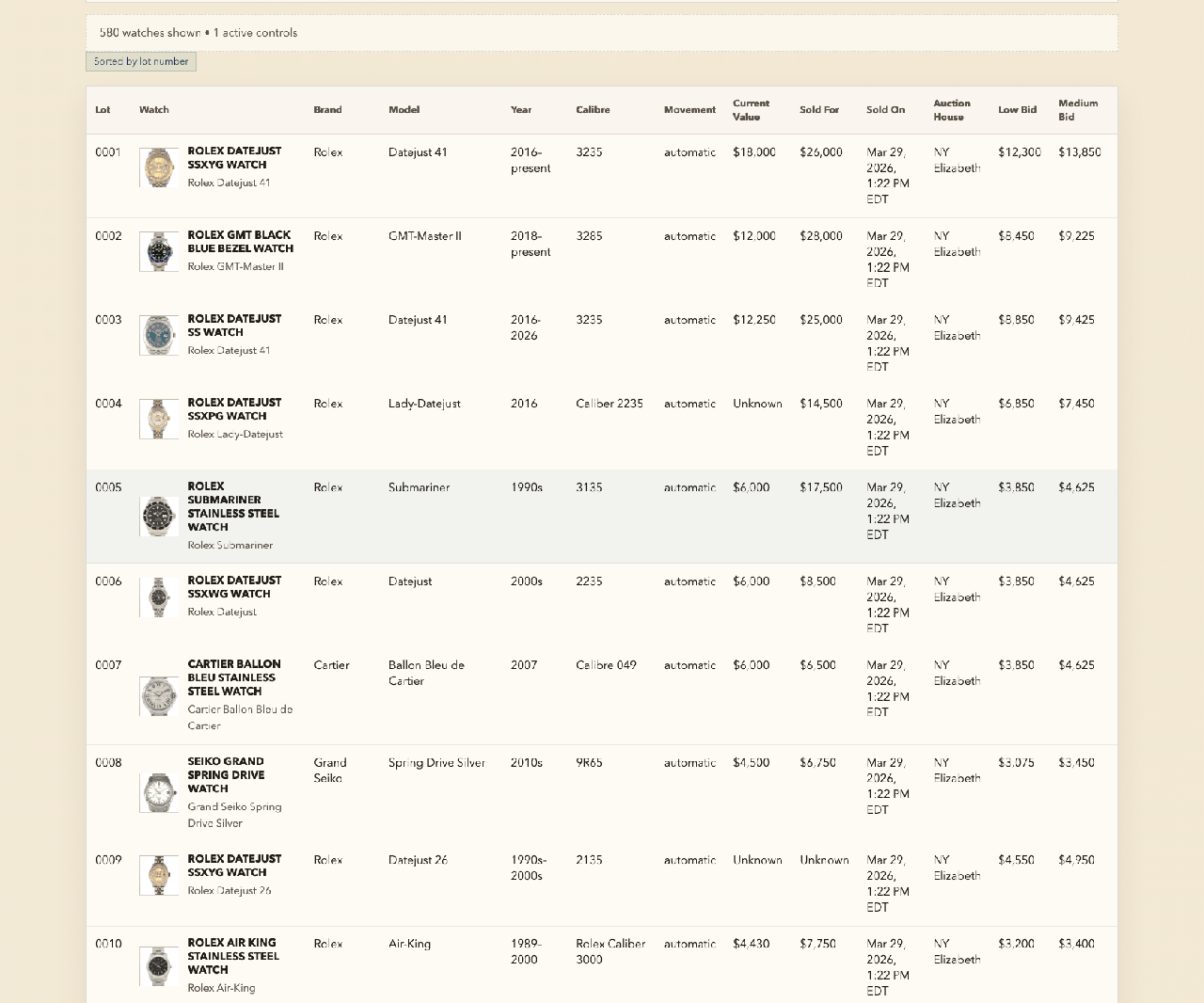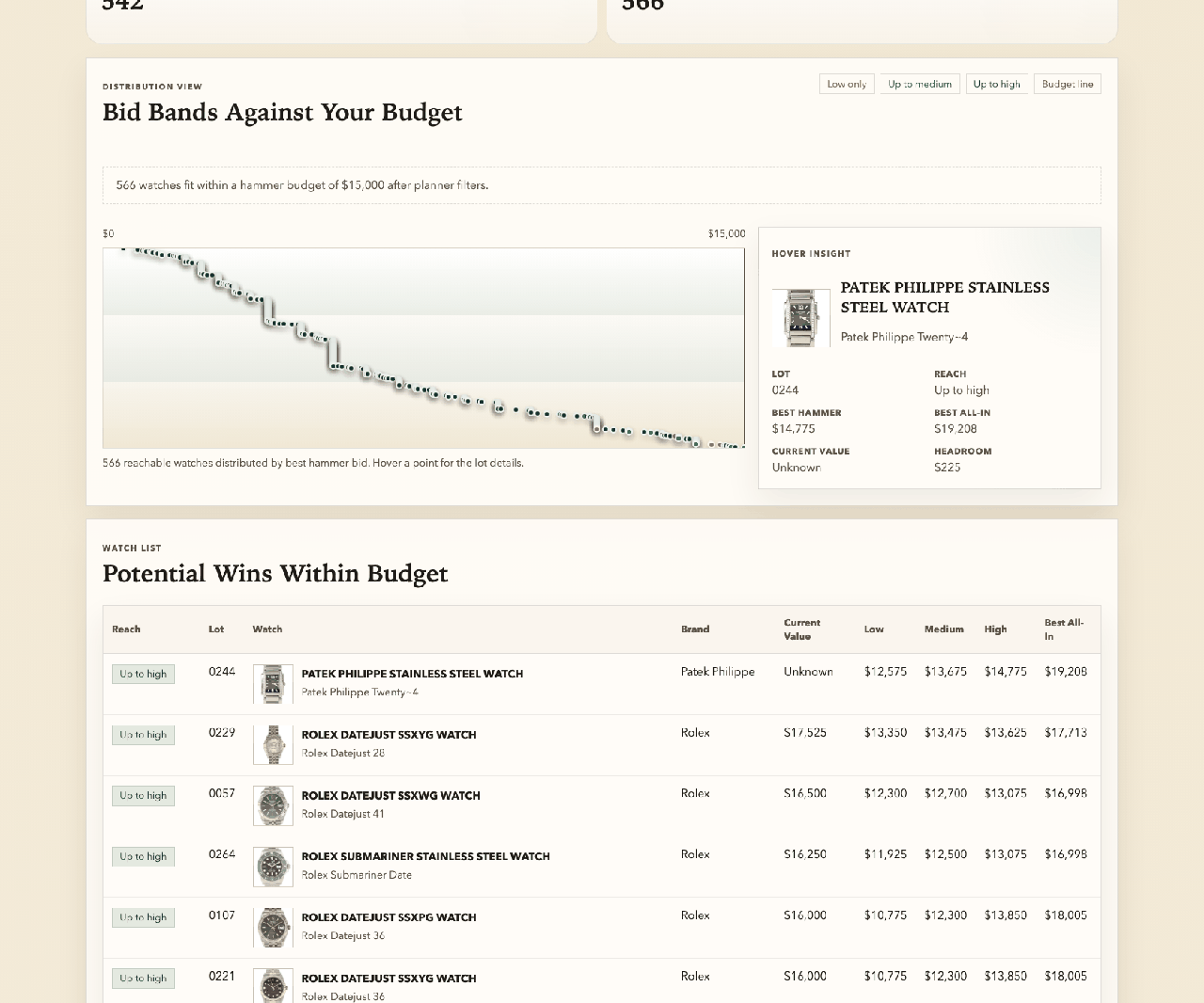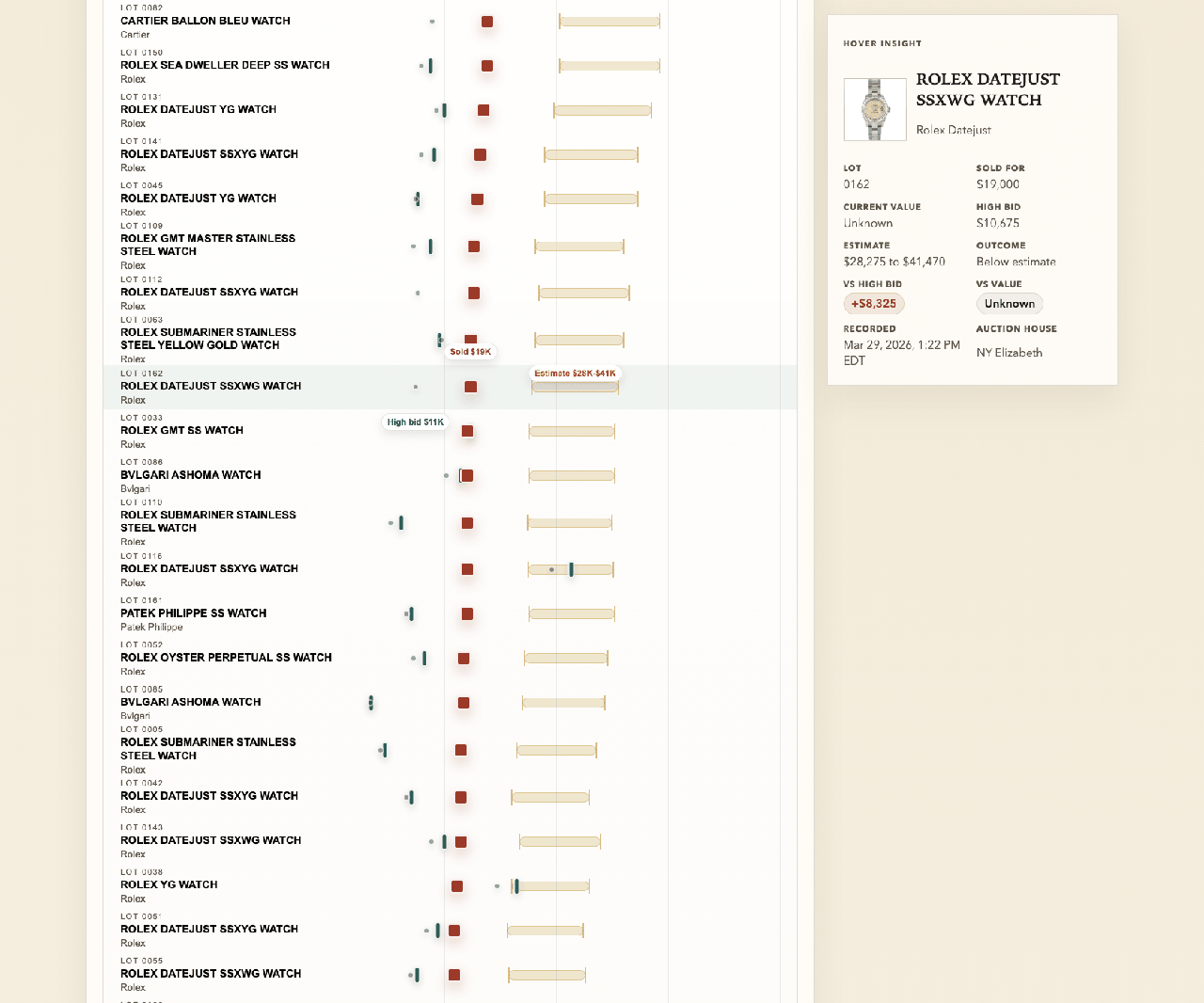
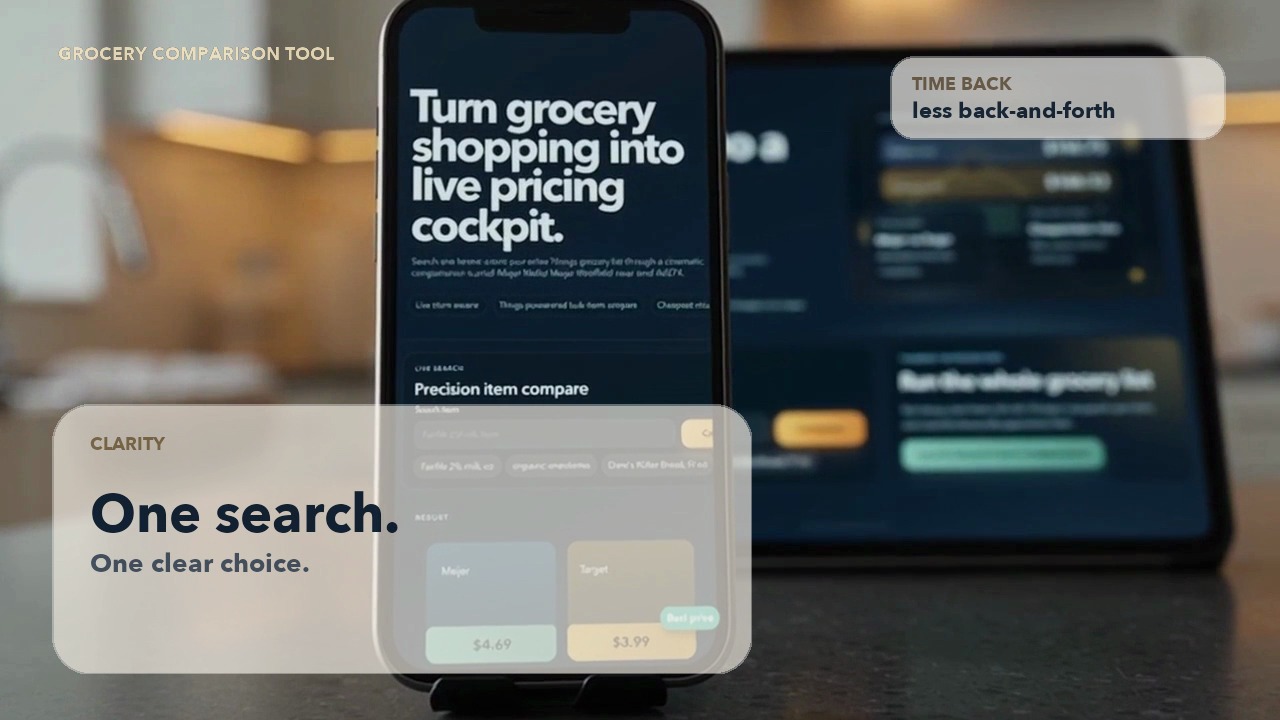
If you read my last post, you saw the finished product: a full research platform for 580 watches from a single auction catalog. Bid recommendations, market values, budget planning, sold-price analysis. The whole thing built in an afternoon.
What you didn’t see was the part that actually mattered — the thinking. The bets I placed on myself before I ever typed a prompt. The moments where I had to be surgically specific, and the moments where I could wave my hand and say “you figure it out.” The quiet calculus of do I actually know enough about this to trust what comes back?
This post is about that part. Not a recipe — more like the conversation I’d have with you at a bar if you asked me “okay, but how did you actually do it?”
The Four Bets
Before I typed a single word into Codex, I was making bets. Not consciously — I didn’t sit down and write them on a napkin. But looking back, the entire project hinged on four assumptions I made about myself, the tools, and the world. If any one of them had been wrong, the whole thing would have collapsed.
Bet #1: The tools are good enough to do this.
This is the one most people get stuck on. They think: Can AI actually build a working app from a conversation? And the answer, a year ago, was “kind of, but you’d spend more time fixing things than building them.” The answer today is different. I’d been watching the tools evolve: tinkering with Claude and Codex and I had a gut feeling that we’d crossed a threshold. Others online agreed: there was a turning point around November of 2025.
Bet #2: The information I needed was actually out there.
Here’s the thing about watches: the secondary market is obsessively documented. Every reference number. Every caliber. Every production year. Sites like Chrono24, Bob’s Watches, EveryWatch — they’ve been cataloging this stuff for years. Phillips and Sotheby’s publish their auction results. Brand enthusiasts run forums with more detail than most academic databases.
I was betting that an AI with vision capabilities could look at a photo of a watch, cross-reference it against the title and description from the listing, and find the real data: the reference, the caliber, the market value, the historical MSRP. Not because the AI “knows” watches — but because the information exists in enough places online that it could piece it together.
This bet was that the wisdom of the masses for watches is valuable in aggregate, and not statistically barbelled (lots of bad info counterbalanced with some expert info).
I knew the watch world was data-rich. If I’d been trying to do this with, say, the correlation of fiscal policy with stock market fluctuations (or some other wonk area I have no business being near), the bet would have been much riskier. The richness of information in your domain is a prerequisite. Know your landscape before you ask an AI to navigate it.
Bet #3: I know enough about watches to evaluate what comes back.
This is the sneaky one. The bet that’s easy to overlook and dangerous to get wrong.
I’m not a watchmaker. I’m not an appraiser. I can’t look at a movement and tell you whether it’s a good one, an accurate one, a certified one or whatnot. But I’ve spent years reading about watches — absorbing the culture, the brands, the price ranges, what’s a stylistic preference vs what’s true horological mastery. I know that a Cartier Tank Française in stainless steel shouldn’t be valued at $15,000 on the secondary market. I know that a quartz Omega is a very different animal from a mechanical one. I know enough to squint at a reverse panda dial and think: that may not appeal to everyone, but I love it.
That accumulated experience (let’s not conflate it with wisdom in my scenario) — the ability to smell when something is off — is what makes the whole process work.
The AI does the heavy lifting. You do the quality control. But you can only do quality control if you have some baseline understanding of what quality means, what it unlocks for you and what it doesn’t protect you from.
In other words, you don’t need to be an expert. You need to be a curious amateur who’s done their homework and understands their risks and blind spots.
I’ll come back to this one. It matters more than you think.
Bet #4: The bid recommendations would be financially sound.
This was the scariest bet. Because the other three are intellectual exercises — interesting to think about, low stakes if you’re wrong. But Bet #4 is the one where real money enters the picture. If I was going to use this tool to actually bid on watches, the numbers had to be grounded in reality. Not hallucinated. Not optimistic. Not based on some training data from 2022 that doesn’t reflect the current market.
I spent the most time here. Questioning the methodology. Challenging specific lots. Asking the AI to show its work. And I’ll walk you through exactly how that went — because this is the part where being specific in your prompts goes from “nice to have” to “this is where your money is.”
Where I Was Specific (And Where I Wasn’t)
If there’s one thing I want you to take away from this post, it’s this: knowing when to be precise and when to let go is not just an important skill. It’s the whole ball game.
It’s not about writing perfect prompts. It’s about knowing which parts of the problem you need to define and which parts you can hand off.
The Opening Prompt: Specific Where It Mattered
Here’s the first thing I typed into Codex. This is the real prompt — unedited, exactly as I wrote it:
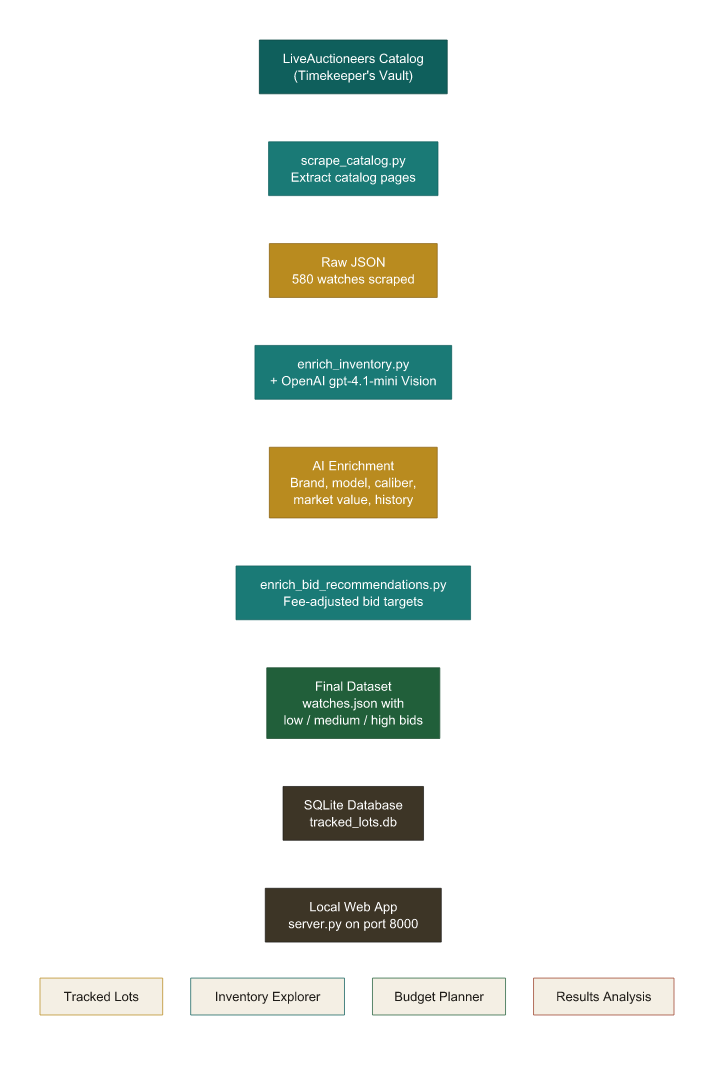
“I need you to do some tedious research. On this site: [LiveAuctioneers URL] is a series of watches – 580 watches across 24 pages. I need you to compile a full inventory of the following:
1) an image of each watch
2) gather information about the watch from its title and then, with the image, find out exactly the make and model and calibre of each watch.
3) Find the brand of the watch, its model, it’s most likely year of production, its calibre, and if it’s automatic, manual, or quartz
4) Find any notable features…
5) Research and find out the approximate cost to purchase it new…
6) What that purchase cost would be in today’s USD
7) What the approximate value for the watch is today from sites like Chrono24, Bobs Watches…
8) any other interesting information…Compile this information into a table and then use that table to generate a web app…”
Look at what I was specific about:
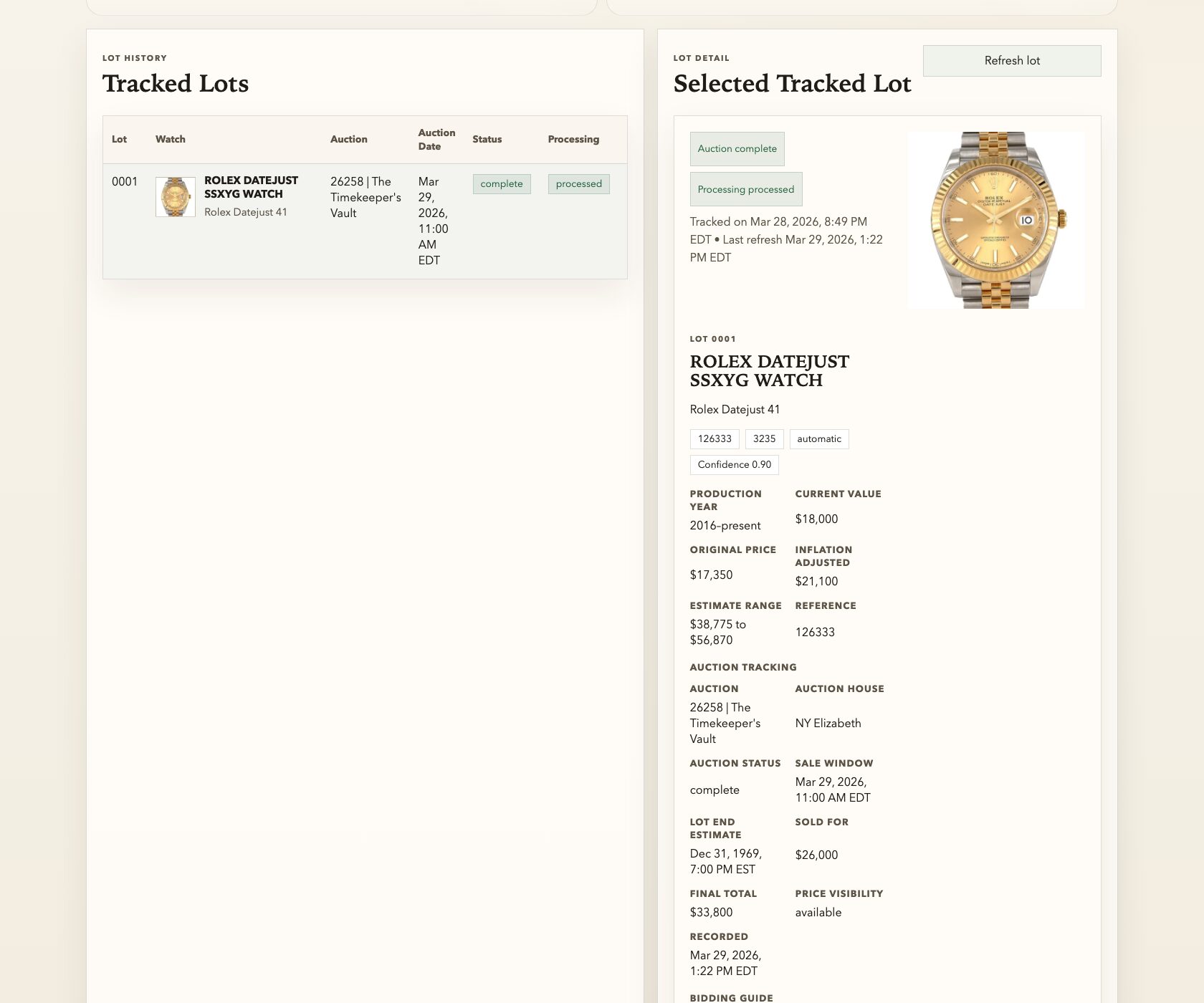
SPECIFIC: The eight numbered data points. Brand, model, caliber, movement type, production year, original MSRP, inflation-adjusted value, current market value. I knew exactly what information I needed for each watch because I’d been reading about watches for years. This wasn’t the AI’s job to figure out — it was mine. These are the columns in the spreadsheet of my brain.
SPECIFIC: The sources. “Sites like Chrono24, Bobs Watches.” I named real places where watch values are tracked. I didn’t say “find the value somewhere.” I pointed the AI toward the actual authoritative sources in the watch world. You know the trusted sources in your domain better than any AI does — name them.
VAGUE (on purpose): “Compile this information into a table and then use that table to generate a web app.” I said nothing about what the web app should look like. No wireframes. No color palette. No layout preferences. I didn’t need to — the important thing was the data structure and the research. The presentation could be figured out later. And it was.
VAGUE (on purpose): “Any other interesting information.” This is my favorite part. It’s an open door. I’m saying: I trust you to notice things I wouldn’t think to ask about. And it did — surfacing details about specific dial variants, bracelet types, and production quirks that I wouldn’t have known to request.
Codex worked for about 40 minutes and came back with 580 enriched watch records and a working web app. Forty minutes. That’s less time than I’ve spent reading a single watch forum thread about whether the Rolex Explorer should have a 36mm or 39mm case. Hey, a guy can dream.
The Enhance Prompts: Trusting the Details
Once I had the base, I started layering. Each prompt added one thing:
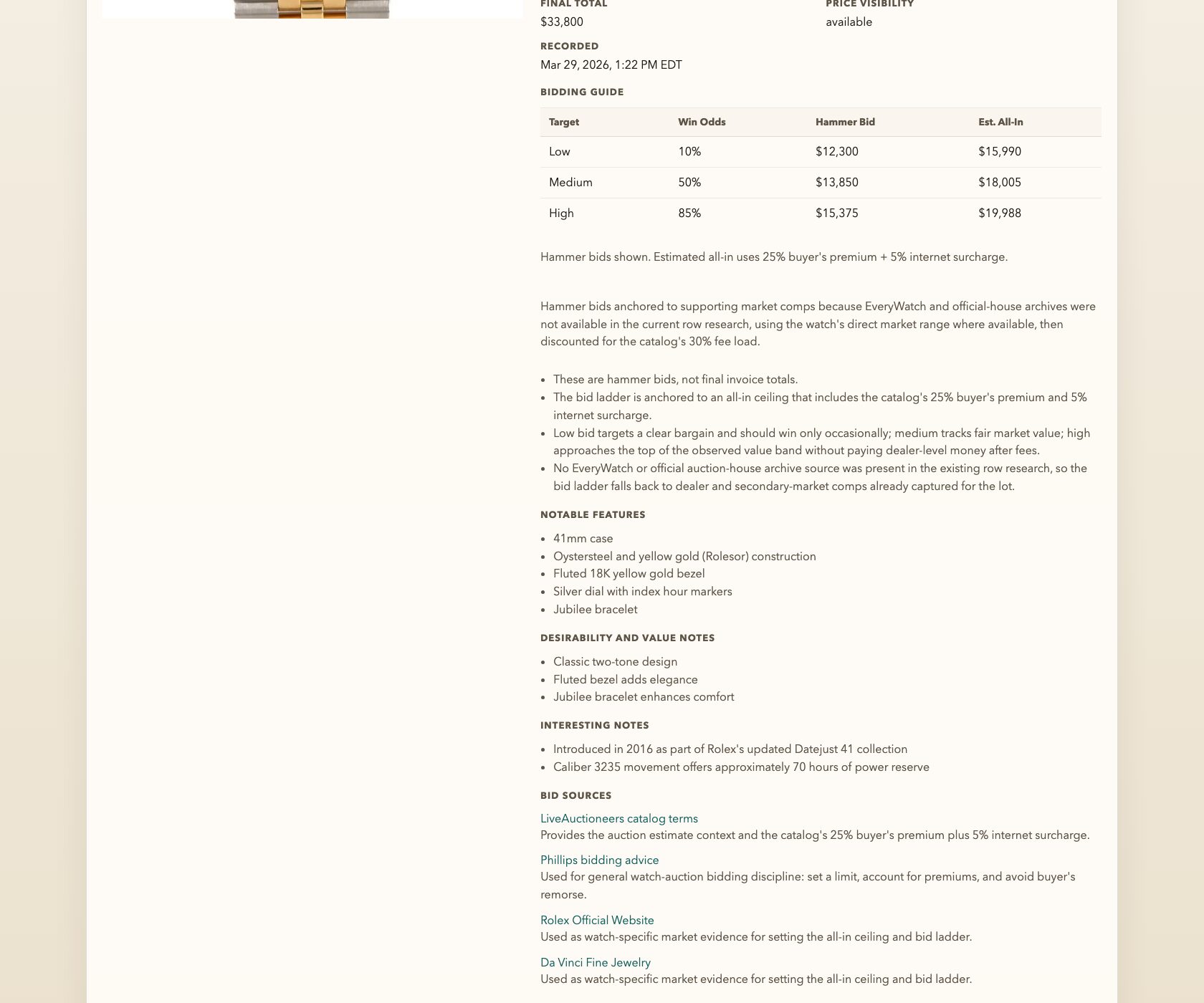
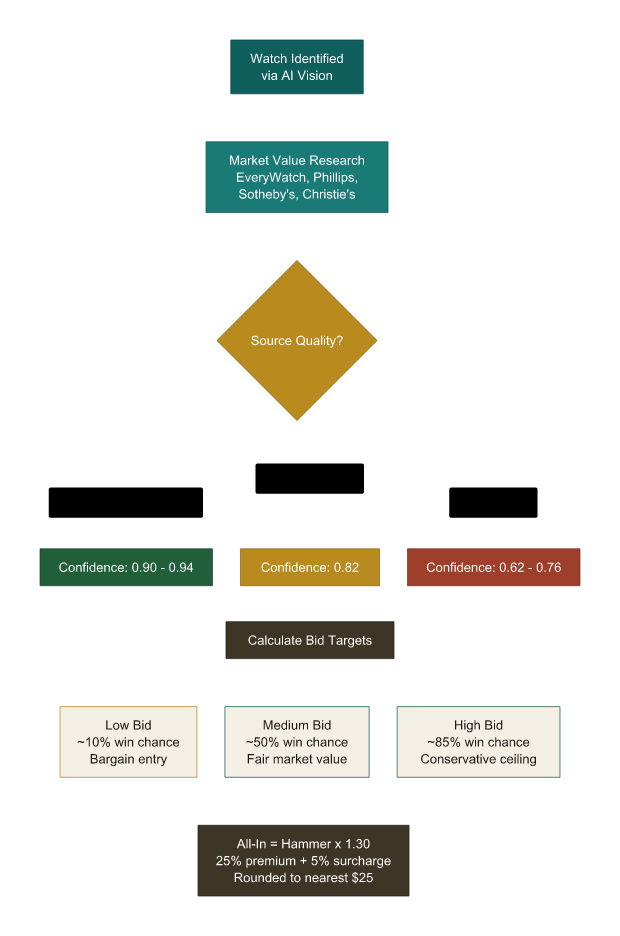
Prompt 2: “This is awesome! Now, let’s enhance: For each watch, add in fields for ‘recommended low bid’, ‘recommended medium bid’, and ‘recommended high bid’…”
SPECIFIC: Three tiers. Low, medium, high. I didn’t say “add bid recommendations” and leave it open-ended. I defined the structure: three distinct tiers, each serving a different purpose. This matters because it forced the AI to think about bidding as a spectrum of risk, not a single number.
Prompt 3: “excellent. next improvement. for the grid and list view, introduce the ability to sort and filter. use your best judgement for what would be good filters, a good user experience, and good UI.”
VAGUE (on purpose): “Use your best judgement.” I didn’t specify which filters. I didn’t pick the sort fields. I didn’t design the UI. Three minutes and 44 seconds later, I had full sorting and filtering that was better than what I would have spec’d out myself. Sometimes the best prompt is permission.
See the pattern? Be specific about what you know. Be vague about what you don’t. If you have strong opinions about the data you need, spell them out. If you don’t have strong opinions about how a dropdown menu should work, don’t pretend you do. The AI is better at UI details than you are. Let it cook.
The Gut Check (Or: That Time I Called the AI’s Bluff)
Remember Bet #3 — the one about knowing enough to evaluate what comes back? This is where it got tested.
The bid recommendations came through. 580 watches, three tiers each. Impressive. Except… some of the numbers felt off. I couldn’t articulate exactly why at first — it was that watch-nerd spidey sense tingling. So I started asking questions.
“what is your methodology for the recommended low bid, recommended medium bid, and recommended high bid? how are you determining those numbers? what research are you doing and using?”
“the bid estimations (low, medium, high) still seem on the lower end to me. explain to me why they are accurate or how we can improve their accuracy. For example: Lot 0152, CARTIER TANK FRANCAISE SS WATCH, shows an estimate range of $10,650 to $15,620 and a current value of around 3300. Do you believe the estimates you have provided are accurate?”
I love this moment. Because the AI agreed with me. It said, essentially: “You’re right, the estimate range was based on original retail pricing and doesn’t reflect the current secondary market. Here’s how we should fix the methodology.” It adjusted. The numbers got better. And I learned something about watch valuation in the process.
This is Bet #3 in action. I didn’t need to be a certified appraiser. I just needed to know that a stainless steel Cartier Tank Française doesn’t sell for $15,000 on the secondary market. That one piece of domain knowledge — a feeling, really, built up from years of casually browsing listings I couldn’t afford — was enough to catch an error that would have thrown off every bid recommendation in the catalog.
Your domain knowledge is the filter. The AI generates. You validate. And you only need to be right enough, often enough, to keep the whole thing honest.
When Things Broke (Because Of Course They Did)
Let me dispel any illusion that this was a smooth, cinematic montage of me typing brilliant prompts and getting perfect results. Things broke. Multiple times. In ways that, if I’m being honest, made me briefly question whether I should have just used a spreadsheet like a normal person who is avoiding reality with “hobbies”.
“im getting a lot of errors when i paste in [URL] to the Track Lot section, and i dont see the previous data we compiled for that lot.”
That was it. No stack traces. No log files. No eloquent description of the error state. Just: “this thing is broken and I am mildly annoyed.” Five minutes later, two bugs found and fixed. Feature working. Crisis averted.
Your only job when something breaks is to describe what you expected and what actually happened. You don’t need to know why. You wouldn’t open the hood of your car and start poking around — you’d tell the mechanic “it makes a grinding noise when I turn left.” Same energy.
The Live Auction (Or: When the App Became Real)
The auction happened yesterday, March 29th, 2026. The Timekeeper’s Vault. 580 watches going under the gavel.
And here’s where the whole project stopped being an interesting exercise and started being a genuinely useful tool. Because as lots started selling, I realized: I have all these estimates. I have all these bid recommendations. And now I have actual sold prices. What if I could see them side by side?
“yes, the auction is going on now… you can now see a ‘Sold For’ price for lot items. Update the site to show the sold for price with today’s date, amount sold for, and auction house that sold it?”
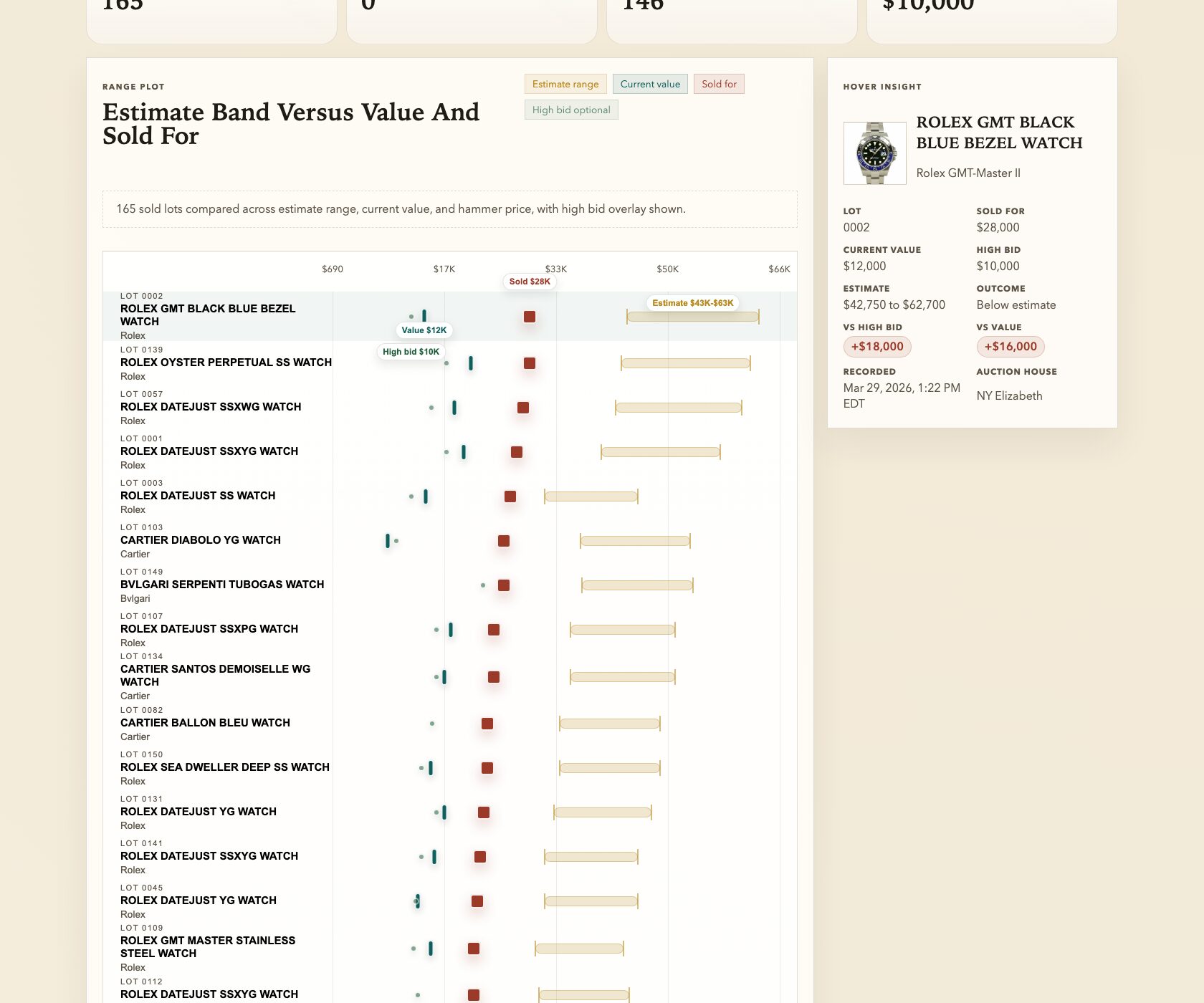
“create a new visualization that shows the variance between each individual watches value, the high bid you recommended, the estimate range, and the sold for…”
These features weren’t in the plan. They couldn’t have been — I didn’t know I’d want them until I was sitting there watching lots close in real time and feeling that itch of wait, I have all the data, why can’t I see this comparison?
The results were eye-opening: 220 out of 243 sold lots went above the high estimate. Ninety percent. I wouldn’t have known that without the variance visualization. And I wouldn’t have had any of it without that first prompt about 580 watches I was too curious to ignore.
And the whole experience was incredible. Watching the live bids, side by side with my tiny app, life altering money flying by in seconds for gorgeous masterpieces of horology. I refreshed LiveAuctioneers constantly. I watched my app show fun facts and details about each lot as it passed. It ingested hammer prices. My heart raced on the three bids I placed so frantically that I went for a run to settle myself.
I surged with pride and astonishment watching my app side by side with the live results. I won a freaking watch with my own hands and work and knowledge! (I totally overpaid, but what a story!)
Recap: What This Actually Takes
1. Curiosity about a specific thing. I didn’t set out to “build an AI app.” I set out to understand 580 watches in an auction catalog. The app was a side effect of the curiosity. If you don’t care about the underlying problem, the whole process will feel like work. If you do care, it feels like play.
2. Enough domain knowledge to ask the right questions — and catch the wrong answers. You don’t need to be an expert. But you need to be the person who’s been lurking in the forums, reading the articles, absorbing the culture of whatever it is you’re interested in. That background knowledge is what turns you from a passive consumer of AI output into an active collaborator.
3. The willingness to say “I don’t really know what I’m doing, but let’s find out.” I made four bets, and they all paid off — but they were real bets. There was a version of this afternoon where the data was bad, the numbers were wrong, and I’d have wasted a few hours. I was okay with that. Because the downside was a lost afternoon, and the upside was exactly what I got.
The Honest Truth About Specificity
Be specific about what you know deeply. I know watches. I spelled out eight numbered data points and named real sources. That specificity made the first prompt effective.
Be vague about what you don’t know. I said “use your best judgment” for the UI. Three minutes later I had something better than I would have designed.
Be specific again when the stakes are high. When real money was involved, I challenged individual lots and asked for methodology. The specificity matched the stakes.
Think of it like this: if you were hiring someone to renovate your kitchen, you’d be very specific about the countertop material and the cabinet layout (because you cook there), reasonably vague about the electrical routing (because you trust the electrician), and very specific again about the budget (because it’s your money). Same principle. Different scenario.
Your Turn (For Real)
I’m not going to give you a fill-in-the-blank template. If this post has done its job, you don’t need one. You need your version of The Timekeeper’s Vault — that thing you’re obsessed with, that collection or dataset or question that nags at you.
Whatever it is, here are the bets you’re making:
- The tools can handle it. (They almost certainly can.)
- The information is out there. (Is your domain data-rich?)
- You know enough to evaluate the output. (Can you smell when something’s off?)
- The stakes are manageable. (Start where the downside is a lost afternoon, not a lost fortune.)
If all four check out? Describe your problem in plain English. Be specific about the data you want. Be vague about the stuff you don’t care about. Ask it to show its work. Push back when something feels wrong.
You’ll be surprised how far one afternoon can take you.
The Prompt Cheat Sheet
| Moment | What I Did | Why It Worked |
|---|---|---|
| The Opening | Listed exactly what data I wanted, numbered, with named sources | Specificity on the data points I knew mattered. Vague on everything else. |
| The Enhance | “This is awesome! Now add [one thing]” | Builds on momentum. One layer at a time. |
| The Delegation | “Use your best judgment for the UI” | Let the AI handle what it’s good at. |
| The Gut Check | “Explain your methodology” + challenged a specific lot | Domain knowledge as quality control. |
| The Bug Report | “This thing is broken, here’s what I tried” | Describe symptoms, not causes. |
| The Evolution | “The auction is live — now show me sold prices vs. estimates” | New features from actual usage. |
Built with curiosity, four bets, and an alarming amount of watch forum knowledge that I can finally justify.